Today’s agent systems can complete tasks. Give them a prompt, and they will produce outputs. But there is a large gap between a system that can brute-force a ticket and one that becomes a better collaborator over time. In practice, most agents still do not internalise a team’s unwritten rules, local conventions, or accumulated corrections. Every new session starts too close to zero. More model intelligence helps, but it does not remove the coordination cost of repeatedly restating context, reimposing guardrails, and correcting the same type of failure modes.
What is missing today is a harness that learns instead of being rebuilt by hand every time. A new task still triggers a fresh round of manual setup. A familiar task with new context still breaks in familiar ways. And a harness that works for one person rarely keeps pace with the way a real team works. Too much operational knowledge still lives in repeated prompts and manual corrections. We believe they should become agent system default behaviours, and we call this shift
Harness Learning
Users are tired of retraining the system
In keynote demos, AI agents look like tireless 10x developers. In real-world codebases, they often feel more like hyperactive interns with the memory of a goldfish. The problem is not just that they get things wrong. It is that they make collaboration feel non-cumulative.
Instead of learning how a team works, many systems force users into the same exhausting loop every time: re-explain the context, restate the constraints, correct the same failure modes, and clean up the damage when the system confidently goes off course. So the productivity story breaks down.
Users are not always saving time, they are simply trading time spent doing the work for time spent babysitting the agent.
Three disconnects sit at the heart of this.
- Every task starts from zero: Real-world tasks run on tacit knowledge and historical baggage. Agents, however, operate in a vacuum. If you don’t explicitly spell out every unspoken constraint, context collapse is practically guaranteed the moment a project scales.
- The real tax is repeated alignment cost: The promise was automation, but the reality is a frustrating career shift, developers have transitioned from writing code to babysitting AI. You aren’t actually saving time; you are just trading the flow state of building for a grueling, zero-trust loop of prompting, verifying, and desperately course-correcting an agent before it confidently spirals down a flawed logic path.
- Users want fit, not just intelligence: Benchmark scores are meaningless when an agent casually nukes three unrelated business flows just to fix one bug. We don’t need a fast-typing cowboy that bloats the repo. We need a reliable system that respects architectural boundaries and doesn’t leave hidden landmines behind.
Benchmark scores don’t contribute much to actual business outcomes. We need an aligned agent system that respects boundaries and doesn’t leave hidden landmines, not a fast-typing cowboy building a “Big Ball of Mud”. The fatal flaw of these black-box agents isn’t making a mistake; it’s making the same type of mistakes repeatedly, ignoring past corrections and trapping users in an endless cycle of babysitting.
Existing fixes help, but only up to a point
As long-running agent systems have improved, a familiar stack of fixes has emerged around them. Some give the model more context. Some give it more memory. Some add stronger prompts, better skills, or more tools. Some introduce more agents, more review loops, or more evaluation. These fixes are useful. Many of them are necessary.
But they operate at a single layer of the system.
That is the limitation. Real production failures are rarely local. A system can look stronger at one step and still remain brittle as a whole.
What existing fixes do and where they tend to stop
- Larger instruction files make expectations more explicit. But there is a limit to how much behaviour can be governed through a larger and larger instruction surface. OpenAI puts the tradeoff plainly: “too much guidance becomes non-guidance.”
- Memory systems reduce the cost of starting from zero. But remembering prior context is not the same as turning past correction into better behaviour. Long-running agents still suffer from “memory-induced drift” and “unbounded context growth.”
- Specialised skills improve local capability. But local capability does not guarantee system-level reliability. Anthropic’s recent long-running agent work suggests that local prompt and harness improvements eventually hit ceilings.
- Critics and evaluators can catch mistakes that generation misses. But the need for a separate evaluator is itself evidence that reliability is a workflow problem, not just a generation problem.
- Stronger single agents raise the capability ceiling. But more capable models do not automatically become better collaborators inside an underspecified system. OpenAI’s own account is telling here: many failures came not from model incapability, but from the surrounding environment being underspecified.
- More agents can improve decomposition and parallelism. But they also introduce more interfaces, handoffs, and chances for intent to be lost. Google Research shows both sides clearly: multi-agent systems can help a lot on some tasks, but degrade performance on others when coordination does not match task structure.
- Evals and observability make failures legible. But diagnosis alone does not make the system adapt. Current agent guidance treats evals as essential for development, yet they still need some mechanism that converts repeated failure patterns into new default system behaviour.
- Human approval gates reduce risk at critical steps. But they usually do not accumulate. A human can catch the same class of mistake ten times in a row, and the system may still require the same check on the eleventh.
The bottleneck has moved
Long-running agent systems have reached a point where the main constraint sits at the system layer.
The challenge is no longer just the capability of any one component. It is the harness that coordinates the workflow: how work is decomposed, how context is carried forward, how interfaces are defined, how review is received, and how behaviour changes through repeated use.
That is where production failures tend to emerge. An agent system can have a stronger model, better memory, or more agents, but still fail at the level that matters most: the harness. Progress now depends on making that harness more reliable.
What agent systems need next is accumulation, not one-off patch.
Repeated correction should not remain a manual intervention. It should change the default behaviour of the system. That requires a missing layer: the harness, and the ability for that layer to evolve through use.
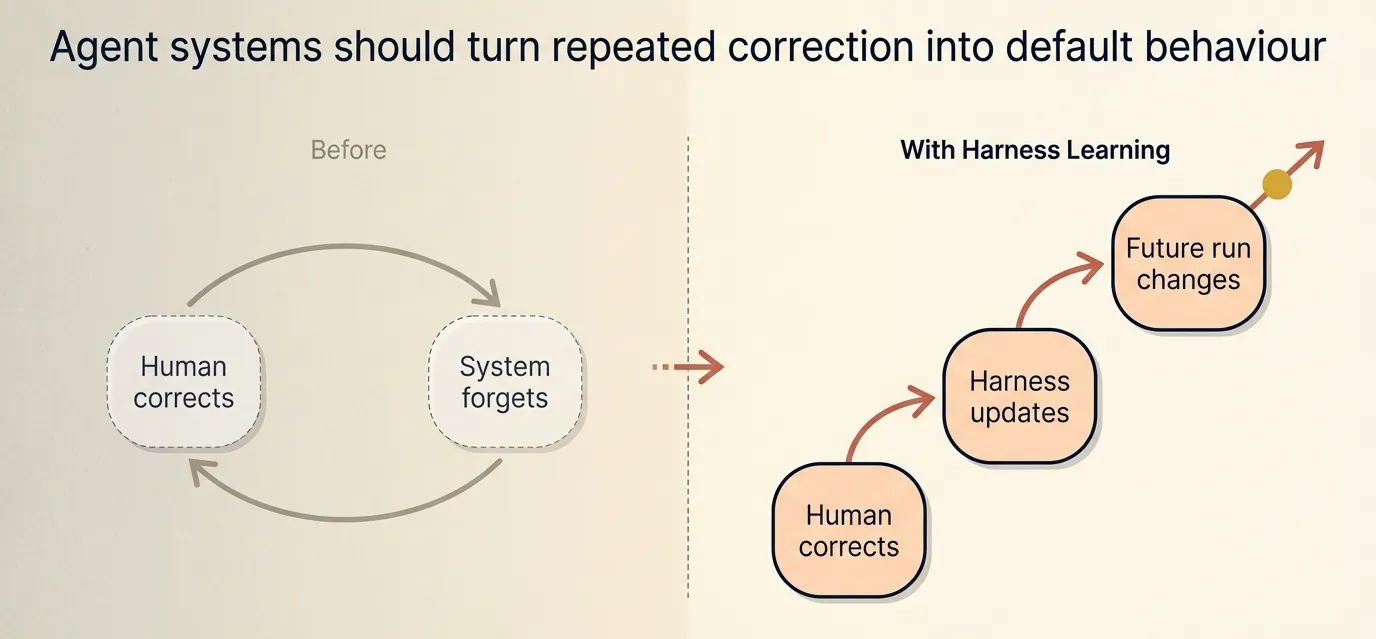
Harness Learning - The Missing Mechanism
To talk about Harness Learning, we first need to define the harness.
The harness is the execution layer around the model: the system that decides what the model sees, what tools and memory it can use, how work is broken down, how outputs are checked, and what carries over to the next step.
This distinction matters. A model can look stronger at one step and still remain unreliable as a system. Most persistent failures actually come from the surrounding system, such as bad decomposition, weak interfaces, missing constraints, poor state management, and corrections that never stick.
That is the harness, the operational layer that turns model capability into governed work.
From harness engineering to harness learning
Once the harness is visible, the next point is obvious: it should be adapted by agents, in the same way humans learnt to reshape tools and, through them, the world around them.
Serious agent systems already rely on harness engineering. Teams tighten prompts, restrict tools, reshape workflows, add review gates, and patch execution logic after failure. That work matters. In many cases, it matters more than another marginal gain in the model. But it is still mostly manual: a failure happens ➙ someone inspects it ➙ someone patches the harness. The system improves, but only because a person re-engineered the layer around it.
Recent work on meta-harness points in the right direction. It treats the harness itself as something that can be optimised, rather than treating the model as the only object that matters. That is an important shift.
But it is still not the same as Harness Learning.
Meta-harness improves the harness through search over code, scores, and execution traces. Harness Learning asks a different question: how should the harness change through real use, especially through repeated human correction inside deployment?
That difference matters because the most important failures in production are often not benchmark failures. They are real use failures. They appear in what users rewrite, what they block, what they escalate, and what they refuse to correct twice.
Harness Learning from Human Feedback
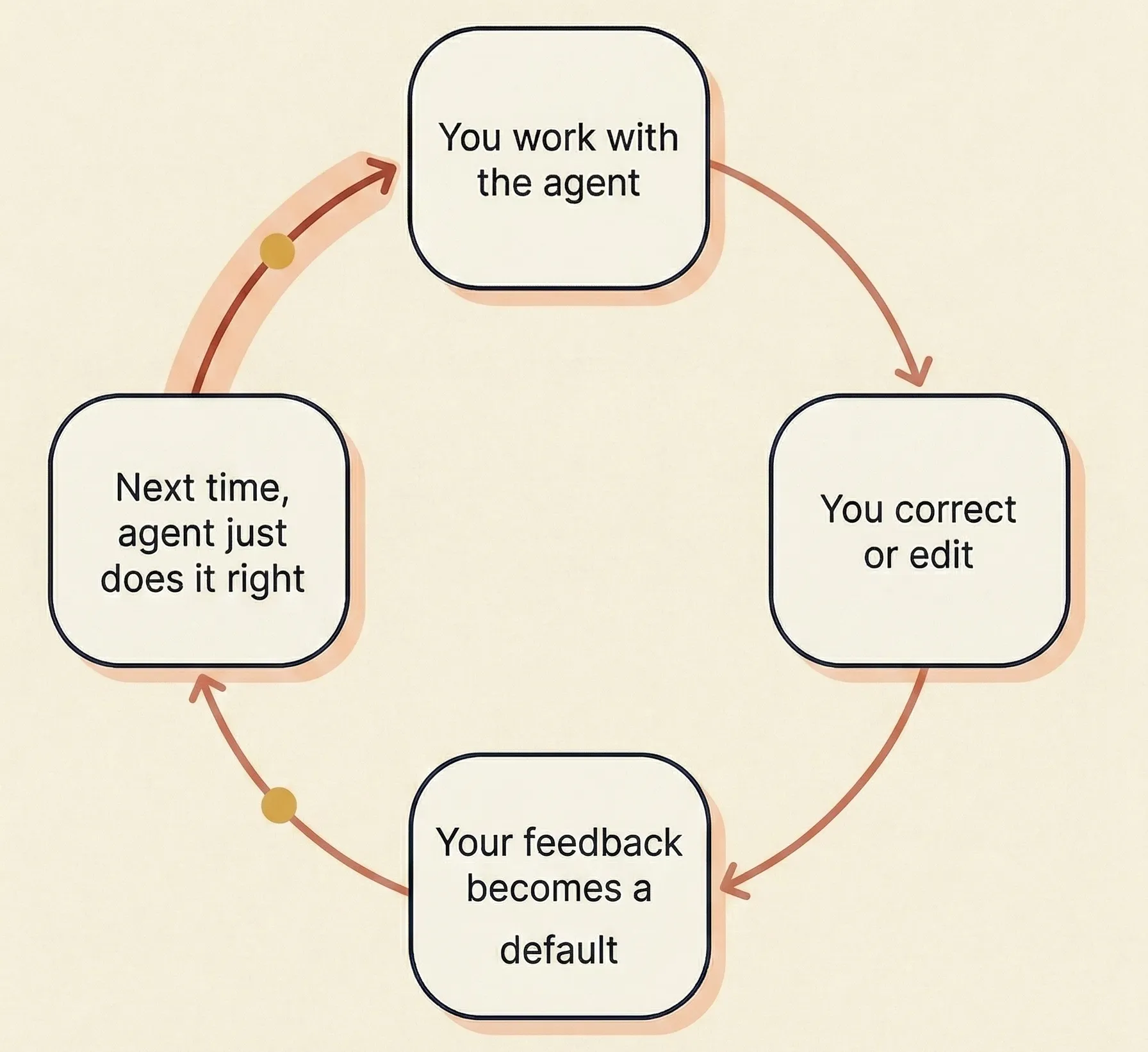
We define Harness Learning as the continual adaptation of the harness through accumulated human feedback from real use, so that feedback in one run becomes default behaviour in the future.
The key idea is carryover: a boundary explained five times should become a default, not a recurring reminder; a failure caught repeatedly should become less likely by design, not just easier to notice; a team’s way of working should become part of the system’s operating pattern, not remain trapped in chat history and human vigilance.
This is why human feedback sits at the centre. The most valuable signal in deployment is often not a scalar reward. It is the structure of intervention around real work: what gets edited, what gets blocked, what gets approved immediately, what triggers escalation, and what keeps recurring after correction. That is where tacit standards become visible.
Harness Learning turns those signals into inherited system behaviour.
The goal is not a more complicated harness. It is a more fitted one: a system that becomes more stable, more aligned, and less expensive to work with over time.
Designing for Harness Learning
Strong teams compound by turning repeated correction into structure. Agent systems that learn from human feedback need the same property. Feedback has to change the harness. This requirement leads to a set of design principles.
How strong human teams compound
Strong teams do not keep solving the same coordination problem from scratch. Their edge compounds because repeated correction gets absorbed into the way they work. This learning does not live in any one person’s mind. It lives in the structure around the work. Over time, the team spends less energy re-explaining itself because more of its operating knowledge has become shared.
Deliverable artefacts sit at the centre of this process. Good teams do not coordinate through conversation alone. They coordinate through briefs, specs, drafts, tables, tickets, memos, and comments. These artefacts carry more than work: decisions, constraints, open questions, and traces of prior correction. They give feedback and learning somewhere to land.
The same pattern appears in review. High-performing teams do not spread attention evenly across every step. They place review where risk concentrates: before a critical handoff, around a high-stakes judgment, or at the point where a mistake becomes expensive to unwind. Recurring feedback then changes the workflow itself.
That is how strong human teams compound. The gain shows up in lower coordination cost over time: their work moves with fewer reminders, fewer recoverable mistakes, and less manual rescue.
Agent systems that aim to learn from human feedback need the same property.
Design principles
Once human feedback is treated as the mechanism through which collaboration compounds, four design principles follow.
- Harness as the learning target: The aim is to improve how the system works over time, not only what it outputs on a single run. Human feedback often points beyond the output itself, e.g. missing constraints, poor routing, or brittle handoffs. Those failures sit at the level of the harness. That is where learning should land.
- Artefact-centric decomposition of work: For feedback to accumulate, work has to become legible. Tasks should move through explicit artefacts that make intermediate work visible, reviewable, and revisable. These artefacts also give correction a durable surface. If the workflow exists only in conversation, very little can compound.
- Learn from human feedback: The strongest signals usually appear in human feedback around real work, e.g. things get reviewed, rejected, escalated, or repeatedly fixed. A system designed for Harness Learning should treat these actions as evidence of how the harness should change. The point is to extract the pattern behind the feedback and turn it into better future defaults.
- Stable defaults, local context: Harness Learning requires the right scope of carryover. In a structured workflow, some feedback is specific to the current case, some should update the defaults of a workflow, and some may reflect a broader user-level preference across workflows. A system designed for Harness Learning should separate these layers clearly. Otherwise, local exceptions get overgeneralised, while stable patterns fail to persist. The point is to preserve feedback at the right level.
The goal of harness learning is long-term fit. Strong human teams become more effective because collaboration compounds: continual feedback changes how work flows. Agent systems that learn harness from human feedback should aim for the same outcome. Feedback should reshape defaults, not only rescue the current run. The question, then, is what a system has to look like for that kind of learning to happen in practice.
How Harness Learning Works
For Harness Learning to work in deployment, feedback has to become durable, scoped, and actionable. In our system, that happens through three design choices: task is made explicit as a structured flow, harness is layered by scope, and human feedback is routed into controlled updates.
Introduce legibility by AgentFlow
We treat each user task as an AgentFlow, a heterogeneous multi-agent workflow organised around explicit artefacts. This is to make intermediate work visible, inspectable, and reusable, so that user feedback has a durable interface.
Artefacts are first-class citizens in AgentFlow. They are where decomposition becomes legible, where review becomes concrete, and where feedback can attach to something more stable than a transient exchange in chat. A good intermediate artefact carries decisions, assumptions, open questions, and traces of prior correction forward through the AgentFlow.
This structure also allows different agents to be used where they fit best. In our system, agents are treated as shared libraries, i.e. reusable execution units with distinct strengths that can be called into a workflow where they add the most value. One step may rely on Claude Code for logic-heavy analysis and structured reasoning; another may use Gemini CLI for multimodal generation or analysis. The advantage comes from composing these heterogeneous capabilities inside a single artefact-centric workflow, with explicit handoffs and explicit outputs at each stage.
That is what gives feedback somewhere to land. In a purely conversational system, correction is easy to give and lose at the same time. In an artefact-centric flow, an edit can be tied to a specific intermediate output, a rejected handoff can be tied to a specific transition, and a repeated intervention can be tied to a recurring weakness in the workflow. Human feedback becomes visible as part of the system, rather than remaining trapped in user vigilance.
That visibility is what makes Harness Learning feasible. More importantly, it also introduces reliability. Once feedback is attached to explicit artefacts and explicit flow structure, the system has a much stronger basis for deciding what should persist, what should remain local, and what should change the next time similar work runs.
Layer Harness by Scope
A collaborative system needs persistence. The harder question is what should persist, and where.
We organise harness state across four levels: System, User, Task, and Worker. The System level stores shared harness components used across users, such as common skills and tools, baseline behavioural policies, and default fallbacks. The User level stores cross-task preferences for a person, such as source preferences, tone, and risk posture. The Task level stores harness state for a specific AgentFlow, such as evaluation criteria, modelling assumptions, or task-specific weighting schemes. The Worker level stores step-local requirements for execution, e.g. runtime environment, tool access, and execution constraints.
This separation matters because feedback arrives at different levels of generality: some signals reflect a stable user preference; some belong to one workflow; some only make sense inside a single step. Systems that collapse all of this into one undifferentiated memory tend to learn the wrong lesson: local exceptions spread too far, stable patterns fail to stick, and conflicting instructions accumulate.
We materialise these levels through explicit harness layers:
- Instruction layer includes the system prompt,
AGENTS.md,BOOT.md, and examples. - The capability layer contains reusable skills and tools.
- The governance layer holds the persistent structure around execution, e.g. memory, rules, duties, conventions, guides, and etc.
This representation is deliberate. A learnable harness should remain inspectable, editable, and attributable. Once harness state is explicit, updates can be scoped, reviewed, versioned, inherited, and, when needed, rolled back.
Treat Human Feedback as Heterogeneous Supervision
In real use, the most valuable supervision signal rarely arrives as a scalar reward. It shows up through feedback around actual work: users directly edit an artefact, leave a comment, request a retry, select one version and discard another, or keep correcting the same pattern.
We treat these interventions as heterogeneous human feedback, including
- outcome signals: e.g. whether an artefact is accepted, downloaded, rerun, or abandoned;
- process signals: e.g. what sequence to follow, what evidence to gather, or what checks should happen before proceeding;
- preference signals: e.g. source choices, tone, or tolerance for uncertainty;
- comparison signals: e.g. a user reveals a judgement across multiple versions;
- implicit signals: e.g. repeated edits or reruns expose a pattern without ever being stated directly.
This matters because collaborative feedback usually carries more structure than a simple pass-or-fail judgement. Users are often revealing where the AgentFlow broke, what default was missing, what should have been escalated, or what evidence they trust.
The implementation question is where each signal should go. Stable user preferences may belong in user-level memory or conventions. Repeated task-specific instructions may belong in task-level guides or boot logic. Execution failures may require worker-level updates to tools, environment, exception handling, or handoff logic. Hard boundaries may need to surface as rules or duties. High-value examples may be stored as reusable demonstrations. Improvements that generalise more broadly may eventually be promoted to the system level.
Durability helps. Correct routing is what makes the learning useful.
Run Harness Learning as a Controlled Update Loop
At the learning level, we use three operators: append, refine, and remove.
- Append adds new preferences, examples, patterns, or operational knowledge;
- refine updates an existing harness component when it needs rewriting, tightening, or re-scoping;
- remove deletes harness content that has become outdated, duplicated, overly local, or inconsistent with newer evidence.
These operators stay intentionally simple. Long-running systems need learning, as well as restraint. A harness that only accumulates drifts toward clutter and contradiction. A harness that never updates keeps paying the same coordination cost.
That is why we treat this as hierarchical harness learning. Learning across a layered harness requires three higher-level operations, distill, route, and prune.
- Distillation asks whether a local correction reveals a reusable pattern or only a case-specific exception.
- Routing decides which level and which harness object should absorb that pattern.
- Pruning removes stale, redundant, overgeneralised, or conflicting states so the system stays legible as it learns.
This is what lets the system improve without becoming careless. A repeated worker-level correction may reveal a missing task-level guide. A recurring task-level preference may deserve promotion to a user-level default. Some signals should generalise, while many should stay local. Good learning depends on preserving that boundary.
Artefacts and checkpoints are central here. An artefact provides an explicit before-and-after surface: what the system produced, what changed, and what was accepted. A checkpoint provides a controlled moment for approval, rejection, escalation, or rerouting. Together, they make learning governable.
The outcome we care about is long-term fit. The system should need fewer repeated corrections, impose lower coordination cost, and become easier to trust through continued use.
Harness Learning Yields Long-Term Usability
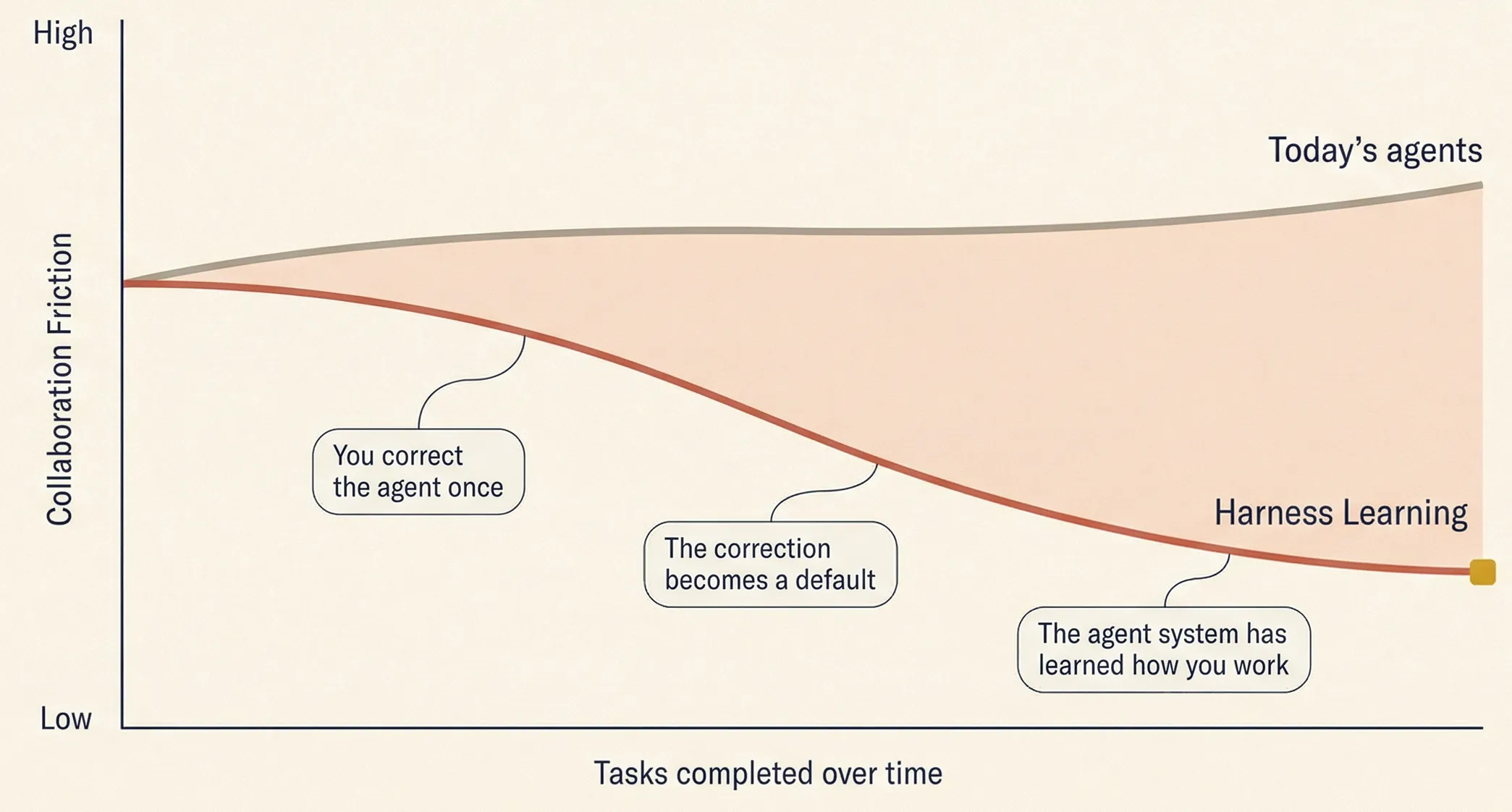
Harness Learning matters because repeated-use agent systems are judged by a different standard from single-run agent systems. A strong single-run agent can succeed by solving a task once under favourable conditions. A long-term collaborator faces a harder test: whether coordination cost falls with use, whether repeated corrections begin to stick, and whether the system becomes easier to trust over time. This difference will become a real boundary for long-term usability. Many agent systems can show single-run impressiveness. Far fewer can absorb feedback in a way that changes how similar work is handled the next time.
This is also why the competitive frontier will shift toward adaptive systems. Better models will continue to matter, and model progress will remain a major source of new capability. Yet once agents enter repeated workflows, another question becomes central: which system improves through use. The advantage then comes from learning which constraints are stable, which review points are worth preserving, which failure patterns should trigger stronger defaults, and which corrections should remain local. Over time, the system with the more adaptive harness may gain a meaningful edge because it compounds fit, not just capability.
Harness Learning also changes what the human-agent interface really is. Chat will remain a useful entry point because it is flexible and easy to use. In serious work, however, collaboration rarely lives in chat alone. It lives in artefacts, handoffs, approvals, retries, escalation paths, and execution constraints. It lives in the structure that determines what gets produced, what gets checked, and what can move forward. As agent systems take on longer and more consequential work, that surrounding structure may matter more and more. The quality of collaboration will depend on whether the harness makes work legible, governable, and able to improve through repeated use.
There is a broader reason this matters. Human organisations already rely on harnesses of their own: briefs, review norms, task boundaries, checklists, and tacit ways of working. Building and refining those structures is often slow, uneven, and difficult to reproduce well. Human-agent harnesses, in many cases, are a translation of that coordination layer into a form agents can follow, inherit, and improve. Agent-agent systems may need this even more, because they have far less ability to repair ambiguity through shared judgement. There is also an economic implication here. In repeated workflows, much of the cost comes from re-specifying context, re-imposing guardrails, and recovering from familiar mistakes. When those recurring corrections are absorbed into the harness, more of that cost can shift into reusable structure.
Harness Learning’s deeper value is that it makes long-running agent systems more human-aligned.